



You are here:
Powerful vector DSP for 5G-Advanced Massive Compute
The Ceva-XC22™ DSP, based on Ceva’s 5th generation Ceva- XC20™ architecture, is the world’s most advanced and efficient vector DSP, targeted for intense 5G and 5G-Advanced workloads in both high-end UE and Infrastructure devices. Ceva- XC22™ supports two independent execution threads and uses Ceva’s unique Dynamic Vector Threading (DVT) scheme to optimally share large vector compute resources, and dramatically increase vector compute efficiency compared to other vector DSP implementations. This dramatic efficiency gain is manifested across a wide range of 5G-Advanced use cases and compute kernels, and solves the biggest pain in vector DSP architectures: how to increase utilization of the most significant resource (in terms of area) in vector DSPs, being the vector arithmetic and compute unit.
Being particularly efficient when handling multiple compute tasks, Ceva- XC22™ is ideally suited for advanced 5G use cases that involve massive and multiple compute needs that are common in 5G UE terminals (e.g. Fixed Wireless Access supporting multiple component carries, or doing various channel estimation tasks) and in Cellular Infrastructure (in both DU/vDU processing and Massive MIMO RRUs) .
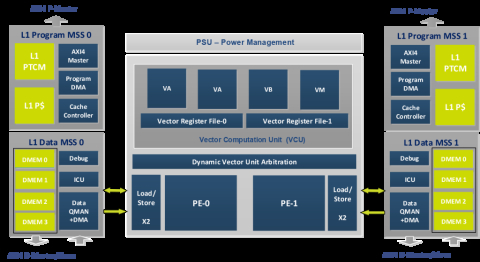
The Ceva- XC22™ DSP is based on a unified scalar and vector-processing platform, using two independent scalar processing elements, each coupled to an independent Program and Memory Sub-Systems, to facilitate true simultaneous and symmetric multithreading operation.
The Ceva- XC22™ uses enhanced Vector Compute Unit (VCU) with two Vector Arithmetic (VA) engines, a Vector Bit & Non-Linear engine (VB) and a Vector Move and Scale engine (VM). These are optimally utilized using the Dynamic Vector Threading (DVT) scheme. Each of the two execution threads has a separate Vector Register file to save vector context, to fully support true HW multi-thread. A novel Dynamic Vector Unit Arbitration schedules simultaneous vector execution commands, per cycle, across the four vector execution units, and resolves run-time contentions. As such, the two execution engines can access the vector resources in parallel. Arbitration dynamically supports wide allocations to one of the processing elements, or symmetric allocations for the two elements. This dramatically increases the VCU compute utilization, as in most cases, tasks can run uninterrupted and do not contend on the vector unit at the same pipeline stage. Efficiency gains can reach 2.5X and more relative to previous generation architecture. The new design concepts boost the performance per area for intense 5G use cases, and significantly reduce the size for implementations requiring large number of cores.
The Ceva- XC22™ supports very wide memory access for efficiently feeding the VCUs. Two load/store units per execution element support 1024-bit access from tightly coupled local data memory. Overall, this constitutes a formidable 2048-bit memory access, achieving unprecedented performance targets for intense 5G and 5G Advanced use cases.
Ceva- XC22™ is also integrated within Ceva’s 5G baseband platforms, The PentaG2-Max for eMBB UE devices, and the PentaG-RAN, for cellular infrastructure, where it is part of heterogeneous compute platforms, including both DSPs and 5G specific compute and acceleration engines.
Being particularly efficient when handling multiple compute tasks, Ceva- XC22™ is ideally suited for advanced 5G use cases that involve massive and multiple compute needs that are common in 5G UE terminals (e.g. Fixed Wireless Access supporting multiple component carries, or doing various channel estimation tasks) and in Cellular Infrastructure (in both DU/vDU processing and Massive MIMO RRUs) .
The Ceva- XC22™ DSP is based on a unified scalar and vector-processing platform, using two independent scalar processing elements, each coupled to an independent Program and Memory Sub-Systems, to facilitate true simultaneous and symmetric multithreading operation.
The Ceva- XC22™ uses enhanced Vector Compute Unit (VCU) with two Vector Arithmetic (VA) engines, a Vector Bit & Non-Linear engine (VB) and a Vector Move and Scale engine (VM). These are optimally utilized using the Dynamic Vector Threading (DVT) scheme. Each of the two execution threads has a separate Vector Register file to save vector context, to fully support true HW multi-thread. A novel Dynamic Vector Unit Arbitration schedules simultaneous vector execution commands, per cycle, across the four vector execution units, and resolves run-time contentions. As such, the two execution engines can access the vector resources in parallel. Arbitration dynamically supports wide allocations to one of the processing elements, or symmetric allocations for the two elements. This dramatically increases the VCU compute utilization, as in most cases, tasks can run uninterrupted and do not contend on the vector unit at the same pipeline stage. Efficiency gains can reach 2.5X and more relative to previous generation architecture. The new design concepts boost the performance per area for intense 5G use cases, and significantly reduce the size for implementations requiring large number of cores.
The Ceva- XC22™ supports very wide memory access for efficiently feeding the VCUs. Two load/store units per execution element support 1024-bit access from tightly coupled local data memory. Overall, this constitutes a formidable 2048-bit memory access, achieving unprecedented performance targets for intense 5G and 5G Advanced use cases.
Ceva- XC22™ is also integrated within Ceva’s 5G baseband platforms, The PentaG2-Max for eMBB UE devices, and the PentaG-RAN, for cellular infrastructure, where it is part of heterogeneous compute platforms, including both DSPs and 5G specific compute and acceleration engines.
查看 Powerful vector DSP for 5G-Advanced Massive Compute 详细介绍:
- 查看 Powerful vector DSP for 5G-Advanced Massive Compute 完整数据手册
- 联系 Powerful vector DSP for 5G-Advanced Massive Compute 供应商
Block Diagram of the Powerful vector DSP for 5G-Advanced Massive Compute
