






You are here:
World's most powerful baseband processor
The Ceva-XC16 is the world’s strongest and fastest vector DSP, built upon the innovative Gen4 Ceva-XC multithread architecture. It is ideally suited to handle the advanced baseband computing needs of modern 5G RAN architectures.
Being a scalable and flexible SDR platform, the Ceva-XC16 can be customized, configured and scaled to address multiple applications, including massive baseband (BBU) aggregation and processing, DU acceleration, OpenRAN deployments, massive MIMO RRUs, multi gigabit modems and ultra-low latency use cases, as well as enterprise and high-end 802.11ax Wi-Fi access points.
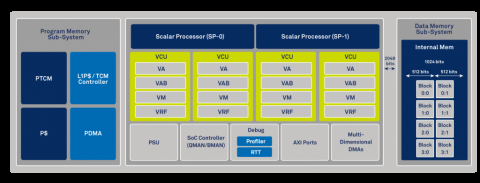
The Ceva-XC16 DSP is based on a unified scalar and vector-processing platform, using two independent scalar cores, sharing the same coherent tightly coupled memory sub-system, to facilitate true simultaneous and symmetric multithreading operation. Combined with an innovative dynamic multithread Vector Compute Unit (VCU) resource allocation scheme, it achieves unparalleled efficiency in VCU usage, handling large multi-user allocations and ultra-short latency. This results in fine resolution of resource allocation in both time and frequency, as is required in modern 5G and Wi-Fi baseband processing applications.
The Ceva-XC16 uses deep pipeline and innovative physical design methods that enables it to achieve unparalleled 1.8GHz clock speeds at 7nm process node, clocking a 256 MAC VCU and 2048-bit wide memory access bandwidth, amounting to the world’s most powerful baseband crunching machine, achieving up to 1600 Giga Operations Per Second (GOPS).
The dual scalar DSP cores are based on the Ceva-BX architecture, enhanced to meet the high speed of 1.8GHz. These provide a 30% improvement in both control code efficiency and code size relative to previous Ceva-XC generations.
The new design concepts boost the performance per area for a typical 5G use case by 50%, which amounts to 35% die area savings for a large cluster of cores, as is typical for many wireless baseband processing infrastructure use cases.
Being a scalable and flexible SDR platform, the Ceva-XC16 can be customized, configured and scaled to address multiple applications, including massive baseband (BBU) aggregation and processing, DU acceleration, OpenRAN deployments, massive MIMO RRUs, multi gigabit modems and ultra-low latency use cases, as well as enterprise and high-end 802.11ax Wi-Fi access points.
The Ceva-XC16 DSP is based on a unified scalar and vector-processing platform, using two independent scalar cores, sharing the same coherent tightly coupled memory sub-system, to facilitate true simultaneous and symmetric multithreading operation. Combined with an innovative dynamic multithread Vector Compute Unit (VCU) resource allocation scheme, it achieves unparalleled efficiency in VCU usage, handling large multi-user allocations and ultra-short latency. This results in fine resolution of resource allocation in both time and frequency, as is required in modern 5G and Wi-Fi baseband processing applications.
The Ceva-XC16 uses deep pipeline and innovative physical design methods that enables it to achieve unparalleled 1.8GHz clock speeds at 7nm process node, clocking a 256 MAC VCU and 2048-bit wide memory access bandwidth, amounting to the world’s most powerful baseband crunching machine, achieving up to 1600 Giga Operations Per Second (GOPS).
The dual scalar DSP cores are based on the Ceva-BX architecture, enhanced to meet the high speed of 1.8GHz. These provide a 30% improvement in both control code efficiency and code size relative to previous Ceva-XC generations.
The new design concepts boost the performance per area for a typical 5G use case by 50%, which amounts to 35% die area savings for a large cluster of cores, as is typical for many wireless baseband processing infrastructure use cases.
查看 World's most powerful baseband processor 详细介绍:
- 查看 World's most powerful baseband processor 完整数据手册
- 联系 World's most powerful baseband processor 供应商
Block Diagram of the World's most powerful baseband processor
