
You are here:
Performance Efficiency Leading AI Accelerator for Mobile and Edge Devices
The NeuroMosaic Processor (NMP) family is shattering the barriers to deploying ML by delivering a general-purpose architecture and simple programmer’s model to enable virtually any class of neural network architecture and use case.
Our unique differentiation starts with the ability to simultaneously execute multiple AI/ML models significantly expanding the realm of capability over existing approaches. This game-changing advantage is provided by the co-developed NeuroMosAIc Studio software’s ability to dynamically allocate HW resources to match the target workload resulting in highly optimized, low-power execution. The designer may also select the optional on-device training acceleration extension enabling iterative learning post-deployment. This key capability cuts the cord to cloud dependence while elevating the accuracy, efficiency, customization, and personalization without reliance on costly model retraining and deployment, thereby extending device lifecycles.
Our unique differentiation starts with the ability to simultaneously execute multiple AI/ML models significantly expanding the realm of capability over existing approaches. This game-changing advantage is provided by the co-developed NeuroMosAIc Studio software’s ability to dynamically allocate HW resources to match the target workload resulting in highly optimized, low-power execution. The designer may also select the optional on-device training acceleration extension enabling iterative learning post-deployment. This key capability cuts the cord to cloud dependence while elevating the accuracy, efficiency, customization, and personalization without reliance on costly model retraining and deployment, thereby extending device lifecycles.
查看 Performance Efficiency Leading AI Accelerator for Mobile and Edge Devices 详细介绍:
- 查看 Performance Efficiency Leading AI Accelerator for Mobile and Edge Devices 完整数据手册
- 联系 Performance Efficiency Leading AI Accelerator for Mobile and Edge Devices 供应商
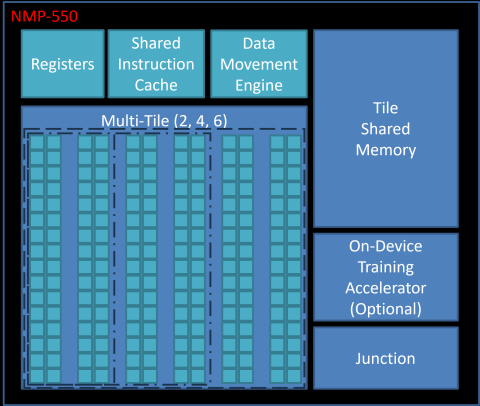
Block Diagram of the Performance Efficiency Leading AI Accelerator for Mobile and Edge Devices

AI IP
- RT-630-FPGA Hardware Root of Trust Security Processor for Cloud/AI/ML SoC FIPS-140
- NPU IP family for generative and classic AI with highest power efficiency, scalable and future proof
- NPU IP for Embedded AI
- Tessent AI IC debug and optimization
- AI accelerator (NPU) IP - 16 to 32 TOPS
- Complete Neural Processor for Edge AI