






You are here:
NPU IP for Embedded AI
Ceva-NeuPro-Nano is a highly efficient, self-sufficient Edge NPU designed for TinyML applications. It delivers the optimal balance of ultra-low power and the best performance in a small area to efficiently execute TinyML workloads across AIoT product categories, including Hearables, Wearables, Home Audio, Smart Home, Smart Factory, and more. Ranging from 10 GOPS up to 200 GOPS per core, Ceva-NeuPro-Nano is designed to enable always-on use-cases on battery-operated devices, integrating voice, vision, and sensing use cases across a wide array of end markets. Bringing the possibilities enabled by TinyML into a reality for low cost, energy efficient AIoT devices.
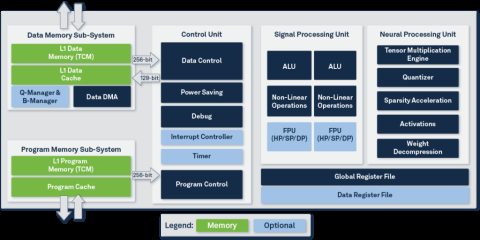
Ceva-NeuPro-Nano is not an AI accelerator and does not require a host CPU/DSP to operate. However, it includes all the processing elements of a standalone NPU, including code execution and memory management. The Ceva-NeuPro-Nano embedded AI NPU architecture is fully programmable and efficiently executes Neural Networks, feature extraction, control code and DSP code, and supports most advanced machine learning data types and operators including native transformer computation, sparsity acceleration and fast quantization. This optimized, self-sufficient architecture enables Ceva-NeuPro-Nano NPUs to deliver superior power efficiency, with a smaller silicon footprint, and optimal performance compared to the existing processor solutions used for TinyML workloads which utilize a combination of CPU or DSP with AI accelerator-based architectures.
Ceva-NeuPro-Nano is not an AI accelerator and does not require a host CPU/DSP to operate. However, it includes all the processing elements of a standalone NPU, including code execution and memory management. The Ceva-NeuPro-Nano embedded AI NPU architecture is fully programmable and efficiently executes Neural Networks, feature extraction, control code and DSP code, and supports most advanced machine learning data types and operators including native transformer computation, sparsity acceleration and fast quantization. This optimized, self-sufficient architecture enables Ceva-NeuPro-Nano NPUs to deliver superior power efficiency, with a smaller silicon footprint, and optimal performance compared to the existing processor solutions used for TinyML workloads which utilize a combination of CPU or DSP with AI accelerator-based architectures.
查看 NPU IP for Embedded AI 详细介绍:
- 查看 NPU IP for Embedded AI 完整数据手册
- 联系 NPU IP for Embedded AI 供应商
Block Diagram of the NPU IP for Embedded AI
