Bluetooth low energy v5.4 Baseband Controller, Protocol Software Stack and Profiles IP









You are here:
Low-power high-speed reconfigurable processor to accelerate AI everywhere.
Zhufeng-800: A low-power high-speed reconfigurable processor to accelerate AI everywhere.
The processor incorporates sophisticated technologies including network random sparsity, adaptive tensor tiling, layer-fusion data movement, and associated tool-chain. The multicore Zhufeng-800 architecture, which is called RiSE, scales from ultra-low-cost single-core applications to ultra-high-performance many-core applications. The architecture is optimized for efficient deep learning, computer vision, and image-video processing.
Efficient architecture for accelerating random sparse deep neural network
By using random pruning schemes, up to 90% redundancy of models can be removed, which can potentially reduce the computational complexity. Most AI inference architectures are unable to fully utilize network sparsity due to the random distribution of nonzero weights. For Zhufeng-800, the pruned networks can be preprocessed by the associated tool-chain. By this means, the Zhufeng-800 can skip the pruned weights during the inference and achieve speedup linearly with network sparsity.
Scalable multi-core architecture for applying in various scenarios
The Zhufeng-800 contains 4 identical cores connected by an internal bus, which can be utilized as building blocks for further configurations. These cores can be configured for different performance requirements. The throughput of 0.6 TOPS can be achieved with only one activated core, while dozens of TOPS can be reached when all cores are activated. Thus, only one core is activated when processing low-cost tasks, while other cores can be reactivated to fulfill the highest performance requirements. The scalable RiSE architecture supports different operating points across product lines: from very-low-cost to ultra-high-performance.
Software programmable and Full stack framework for deployment
The Zhufeng-800 processor is fully software programmable and thus can handle the still rapidly changing deep learning algorithms. The newly-added neural networks or applications can be accommodated by the associated tool-chain for optimized deployment. Therefore, a SoC based on the Zhufeng-800 processing platform can stay in the market despite the regeneration of algorithms or can even address other market segments with a wide variety of customer requests.
Full service including associated tool-chain and the deployment of algorithm will be provided with Zhufeng-800, which includes sparse training, quantitative training, model compilation, and model deployment.
The processor incorporates sophisticated technologies including network random sparsity, adaptive tensor tiling, layer-fusion data movement, and associated tool-chain. The multicore Zhufeng-800 architecture, which is called RiSE, scales from ultra-low-cost single-core applications to ultra-high-performance many-core applications. The architecture is optimized for efficient deep learning, computer vision, and image-video processing.
Efficient architecture for accelerating random sparse deep neural network
By using random pruning schemes, up to 90% redundancy of models can be removed, which can potentially reduce the computational complexity. Most AI inference architectures are unable to fully utilize network sparsity due to the random distribution of nonzero weights. For Zhufeng-800, the pruned networks can be preprocessed by the associated tool-chain. By this means, the Zhufeng-800 can skip the pruned weights during the inference and achieve speedup linearly with network sparsity.
Scalable multi-core architecture for applying in various scenarios
The Zhufeng-800 contains 4 identical cores connected by an internal bus, which can be utilized as building blocks for further configurations. These cores can be configured for different performance requirements. The throughput of 0.6 TOPS can be achieved with only one activated core, while dozens of TOPS can be reached when all cores are activated. Thus, only one core is activated when processing low-cost tasks, while other cores can be reactivated to fulfill the highest performance requirements. The scalable RiSE architecture supports different operating points across product lines: from very-low-cost to ultra-high-performance.
Software programmable and Full stack framework for deployment
The Zhufeng-800 processor is fully software programmable and thus can handle the still rapidly changing deep learning algorithms. The newly-added neural networks or applications can be accommodated by the associated tool-chain for optimized deployment. Therefore, a SoC based on the Zhufeng-800 processing platform can stay in the market despite the regeneration of algorithms or can even address other market segments with a wide variety of customer requests.
Full service including associated tool-chain and the deployment of algorithm will be provided with Zhufeng-800, which includes sparse training, quantitative training, model compilation, and model deployment.
查看 Low-power high-speed reconfigurable processor to accelerate AI everywhere. 详细介绍:
- 查看 Low-power high-speed reconfigurable processor to accelerate AI everywhere. 完整数据手册
- 联系 Low-power high-speed reconfigurable processor to accelerate AI everywhere. 供应商
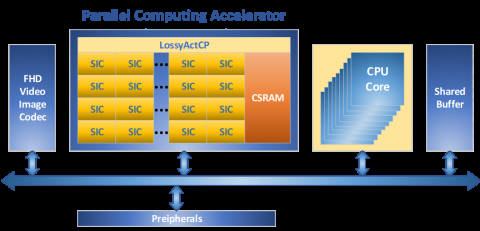
Block Diagram of the Low-power high-speed reconfigurable processor to accelerate AI everywhere.

Low-power IP
- Ultra low-power crystal-based 32 kHz oscillator designed in TSMC 22ULL
- 2.5D Multi-Core Raster & Vector Graphics Processor for low-power SoCs with Microcontroller
- Low-Power Combo Bandgap Voltage and Current References (1.21V/600nA) - GlobalFoundries 0.13um BCD
- Low-Power Wide Range PLL - UMC 130 L130EHS
- Ultra low-power 2.4 GHz transceiver for Bluetooth Low Energy 5
- Low-power 32-bit RISC-V processor