
You are here:
Edge AI Accelerator NNE 1.0
To embed artificial intelligence into countless edge devices, it needs a CPU independent accelerator to speed up the inference to reduce power consumption. with altek NNE 1.0 IP, we help customer to reach this target and time to market.
The latest AI accelerator engine (NNE 1.0) can provide the most power-efficient and highest performing AI inference with high accuracy & quality AI architecture on the market. The architecture is optimized for efficient deep learning and CPU independent to support customer to time-to-market.
Flexible architecture for deep learning for computer vision
NNE 1.0 provides very efficiently AI inference capability and flexible to embed CNNs based AI Engine to any CPU or MCU based device to make the edge device become a smart device. All the computing and intermedium data are all in NNE 1.0 engine without accessing system memory to reduce the memory bandwidth to speed up the AI inference.
Low power extends battery life
Low energy consumption extends battery life of mobile devices and edge computing applications. A new class of computer vision applications, such as human detection / face detection / face recognition / gesture detection for smart sensing devices, require always-on operation, again necessitating ultra-low power consumption. The NNE 1.0 has been architected for low-power operation compared to other solutions on the market.
High-performance enables new applications
Deep learning, computer vision applications, the NNE 1.0 architecture was designed specifically for neural network processing for most of AI applications. The NNE 1.0 has 1440 MACs to reach high performance and low power application to give customer a new user experience.
Scalable architecture
Although the NNE 1.0 has 1440 MACs in current design, but it has scalable architecture to change the computing power based on customer’s requirement.
Production proven
The NNE 1.0 has been product and silicon proven and adopt in NB/security/IOT market.
Easy Use & Full-Featured ToolChain (NNDK: Neural Network Development Kit)
Cooperate with NNDK, customer can easily convert the AI model to device and simulate the quality & performance to shrink the development process time.
The latest AI accelerator engine (NNE 1.0) can provide the most power-efficient and highest performing AI inference with high accuracy & quality AI architecture on the market. The architecture is optimized for efficient deep learning and CPU independent to support customer to time-to-market.
Flexible architecture for deep learning for computer vision
NNE 1.0 provides very efficiently AI inference capability and flexible to embed CNNs based AI Engine to any CPU or MCU based device to make the edge device become a smart device. All the computing and intermedium data are all in NNE 1.0 engine without accessing system memory to reduce the memory bandwidth to speed up the AI inference.
Low power extends battery life
Low energy consumption extends battery life of mobile devices and edge computing applications. A new class of computer vision applications, such as human detection / face detection / face recognition / gesture detection for smart sensing devices, require always-on operation, again necessitating ultra-low power consumption. The NNE 1.0 has been architected for low-power operation compared to other solutions on the market.
High-performance enables new applications
Deep learning, computer vision applications, the NNE 1.0 architecture was designed specifically for neural network processing for most of AI applications. The NNE 1.0 has 1440 MACs to reach high performance and low power application to give customer a new user experience.
Scalable architecture
Although the NNE 1.0 has 1440 MACs in current design, but it has scalable architecture to change the computing power based on customer’s requirement.
Production proven
The NNE 1.0 has been product and silicon proven and adopt in NB/security/IOT market.
Easy Use & Full-Featured ToolChain (NNDK: Neural Network Development Kit)
Cooperate with NNDK, customer can easily convert the AI model to device and simulate the quality & performance to shrink the development process time.
查看 Edge AI Accelerator NNE 1.0 详细介绍:
- 查看 Edge AI Accelerator NNE 1.0 完整数据手册
- 联系 Edge AI Accelerator NNE 1.0 供应商
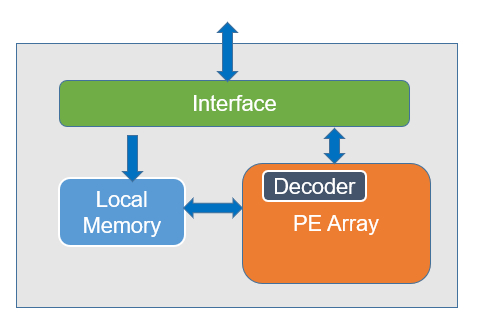
Block Diagram of the Edge AI Accelerator NNE 1.0
