






You are here:
Tensilica Fusion F1 DSP
Smallest and lowest power DSP for narrowband wireless communications and always-on applications
The Cadence® Tensilica® Fusion F1 DSP offers the lowest energy, small footprint, high-performance control and signal processing best fit for narrowband wireless communication, always-on, IoT, and wearables applications. The Fusion F1 DSP is very efficient
The Cadence® Tensilica® Fusion F1 DSP offers the lowest energy, small footprint, high-performance control and signal processing best fit for narrowband wireless communication, always-on, IoT, and wearables applications. The Fusion F1 DSP is very efficient
查看 Tensilica Fusion F1 DSP 详细介绍:
- 查看 Tensilica Fusion F1 DSP 完整数据手册
- 联系 Tensilica Fusion F1 DSP 供应商
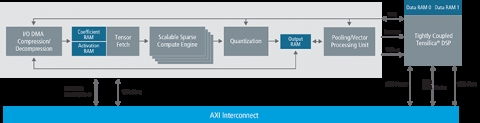
Block Diagram of the Tensilica Fusion F1 DSP
