



You are here:
在功率优化的封装中实现理想性能
Origin™ E2 专为手机和边缘节点等耗电应用而设计。E2 深度学习加速器 (DLA) 无需外部 DRAM 访问,节省了系统功耗,同时提高了性能,降低了延迟,缩减了系统 BOM 成本。其高效引擎的功耗不到 1W,可实现 18 TOPS 的性能。Origin E2 可针对特定工作负载进行调整,从而为独特的应用要求提供理想的性能配置文件。
查看 在功率优化的封装中实现理想性能 详细介绍:
- 查看 在功率优化的封装中实现理想性能 完整数据手册
- 联系 在功率优化的封装中实现理想性能 供应商
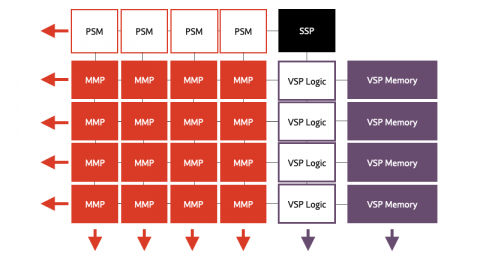
Block Diagram of the 在功率优化的封装中实现理想性能

AI accelerator IP
- AI accelerator (NPU) IP - 16 to 32 TOPS
- AI accelerator (NPU) IP - 32 to 128 TOPS
- Deeply Embedded AI Accelerator for Microcontrollers and End-Point IoT Devices
- Performance Efficiency Leading AI Accelerator for Mobile and Edge Devices
- High-Performance Edge AI Accelerator
- Ultra-low-power AI/ML processor and accelerator