






You are here:
4-/8-bit mixed-precision NPU IP
OPENEDGES, the memory system IP provider, including DDR memory controller, DDR PHY, on-chip interconnect, and NPU IP together as an integrated solution or independent IP. They are tightly combined to bring synergy for high performance and low latency. OPENEDGES released the first commercial mixed-precision (4-/8-bit) computation NPU IP, ENLIGHT, in Feb 2022. When ENLIGHT is used with other OPENEDGES' IP solutions, it reaches maximum efficiencies in power consumption, area, and DRAM optimization.
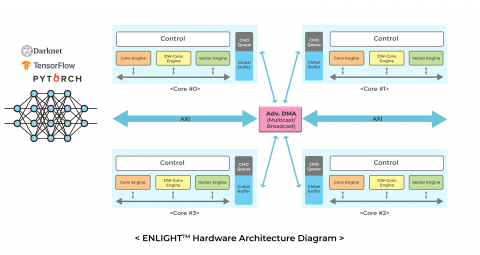
ENLIGHT, a high-performance neural network processor IP, features a highly optimized network model compiler that moves DRAM traffic from intermediate activation data by grouped layer partition and scheduling. Plus, it supports load balancing partition for multi-core NPU. With the industry's first adoption of 4-/8-bit mixed-quantization, it is easy to customize ENLIGHT at different core sizes and performance for the target market applications and achieve significant efficiencies in size, power, performance, and DRAM bandwidth.
A production-proven IP, ENLIGHT, has been licensed in a wide range of applications, including IP cameras, IoT, ADAS, and more.
ENLIGHT, a high-performance neural network processor IP, features a highly optimized network model compiler that moves DRAM traffic from intermediate activation data by grouped layer partition and scheduling. Plus, it supports load balancing partition for multi-core NPU. With the industry's first adoption of 4-/8-bit mixed-quantization, it is easy to customize ENLIGHT at different core sizes and performance for the target market applications and achieve significant efficiencies in size, power, performance, and DRAM bandwidth.
A production-proven IP, ENLIGHT, has been licensed in a wide range of applications, including IP cameras, IoT, ADAS, and more.
查看 4-/8-bit mixed-precision NPU IP 详细介绍:
- 查看 4-/8-bit mixed-precision NPU IP 完整数据手册
- 联系 4-/8-bit mixed-precision NPU IP 供应商
Block Diagram of the 4-/8-bit mixed-precision NPU IP
